システムログを活用をするためのシステムとは?

ログ活用のための仕組みに関して調べた時のノートです。
(きっかけは 稼働ログをもっと活用するには に記載させていただきました。)
ETLツール、DWH、BIツールという単語をこの調査で初めて知った程度のレベルです。
1日しか調べていないので、根本的に間違っているかもしれません。
お気づきの点がございましたらコメント等でご指摘いただけると幸いです。
課題
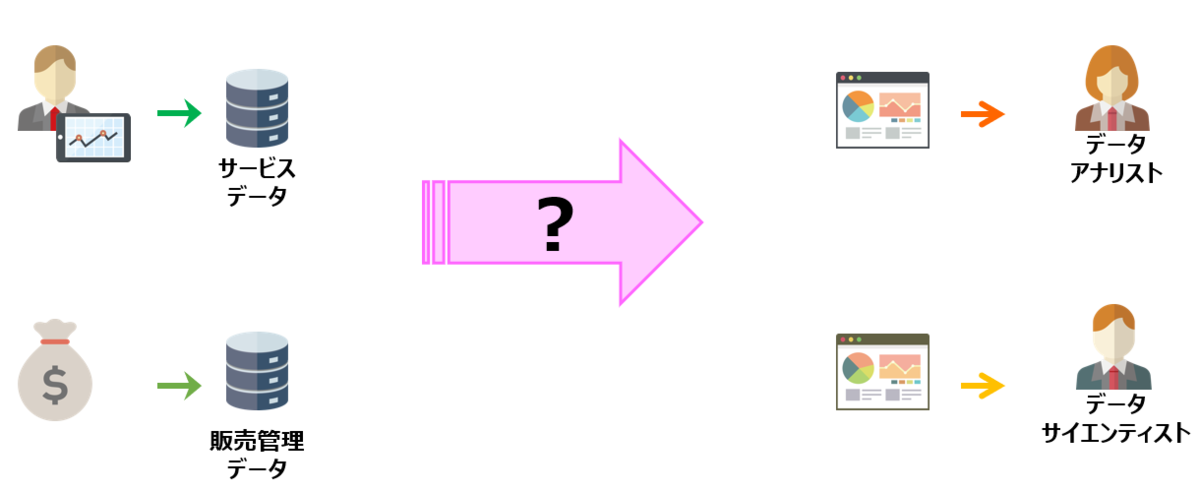
現状
- 様々な場所に蓄積されている
- データが格納されている場所ごとにデータフォーマットが異なる
- それぞれの場所に格納されているデータの種類が不明確
- データの可視化がされていない
- 用途に合わせたデータの加工が十分にできていない
アンチパターン
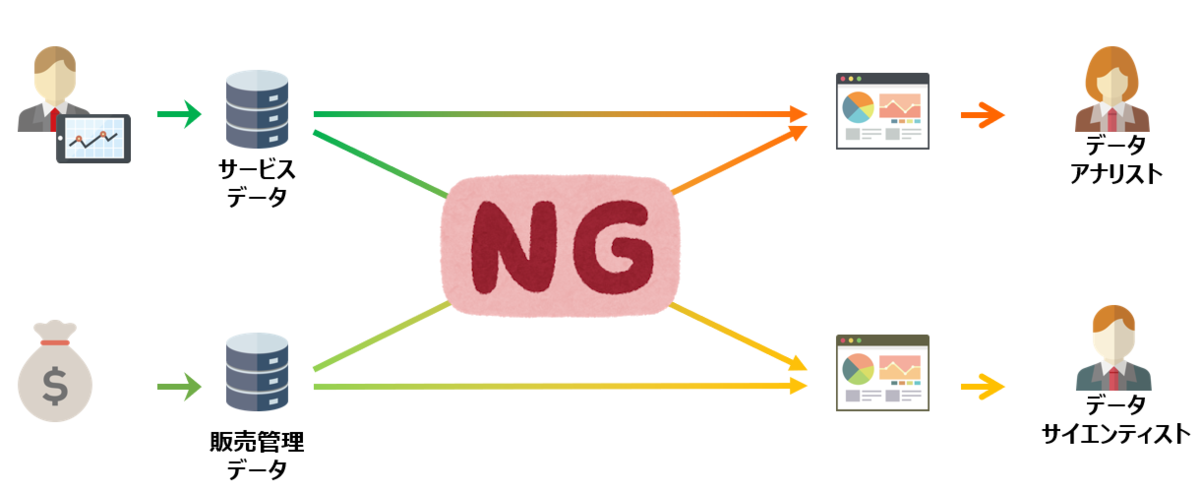
『全てのデータに対応するモニターツール(Viewer)を開発する』のは現実的ではないと判断されている。
問題点
- 対象データが全く同じになるシステムは存在しないため、専用ツールとなってしまう
- 大量のデータを扱うため、Viewerが実施しなければならない処理量が非常に大きい
- 格納されているデータがのフォーマットが、ログ活用に向かない
- 処理量が多すぎてViewerとして機能しない
- Viewerの数だけデータソースを直接読み込むプログラムが必要になる。
- Viewerが動作する際にデータソースを直接読み込むため、データソースへデータ登録を行うシステム側への影響が発生する
- データソース側の仕様変更が、すべてのViewerに伝搬するため、メンテナンスコストが膨大になる。
課題
- データ活用処理がメイン処理(データ格納側の処理)に影響を与えてはいけない。つまりメイン処理と疎結合のシステムである必要がある
- 応答性に優れたシステムである必要がある。
- データが要求されてからデータを作成するのではなく、あらかじめ必要になりそうなデータを用意しておく。
- データ取得に対する学習コストが低い(標準的なフォーマットでデータが格納されている)。
改善提案(一般論)
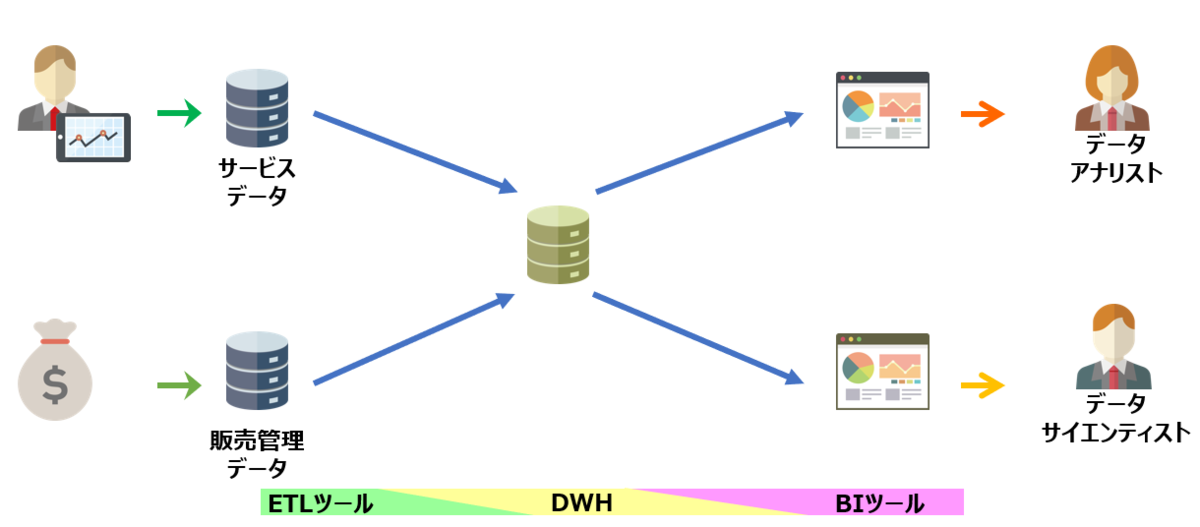
上記の課題を解決するために、一般的にはデータ解析専用のデータベースを用意することが多い
データ解析専用のデータベースには以下の特徴が必要になる
- 分析しやすいデータ
- 検索しやすいデータ
また、蓄積されたデータは時間毎に解析されることが多いので、時系列データとして扱われることが前提
- 時系列
上記システムで目的を達成するためには、データ解析専用のデータベース以外に、データベースへのデータ格納処理、データベースの可視化処理が必要になる。
一般的には、
データソースのことをデータレイク、データ解析専用のデータベースをDWH(データウェアハウス)と呼び、データベースへのデータ格納処理をETLツール、データベースの可視化処理をBIツールというツールで実施することが多い。
| DB | (変換処理) | DB | (変換処理) | 可視化 |
|---|---|---|---|---|
| データレイク | → | DWH | → | ブラウザ |
| ETLツール | BIツール |
ETLツール
ETLツールとはExtract(抽出)、Transform(変換)、Load(書き出し)の先頭を集めた言葉で、複数のシステムからデータを取り出し、DWHへ受け渡す機能をもったツール。
場合によってデータレイクへ直接アクセスする必要があるので、メイン処理側への負荷を考慮する必要がある。
DWH(データウェアハウス)
ストレージの低価格化が進み、情報活用を目的としたデータベースを保持することのコストが低下したため、「DWH(データウェアハウス)」生まれた。
DWHは最初から「活用」を意識したデータの巨大倉庫です。目的が一つ(データ活用)なので、目的達成のために有効な仕組みがあらかじめ用意されている。
DWHは目的別にデータが並べられ、明細データをそのまま時系列で蓄積する。
データの削除や更新も行わないため、膨大なデータを保持し続ける。
DWHには以下の特徴が必要になる
- 分析しやすいデータ
- 共通フォーマット:複数のデータレイクから集められたデータであるが、共通の方法でアクセスが可能
- 詳細データ:解析処理の軽微な変更に対して柔軟に対応ができるように加工前の詳細データが残っている
- 要約データ:あらかじめ目的毎に集計したデータが格納されている
- 時系列データ:時間変化が解析しやすい形になっている。
- 検索しやすいデータ
BI(Business Intelligence)ツール
- DWHとETLによって集約されたデータの分析を分析・可視化を行う
- 目的に合ったデータの加工を実施する
よくある形
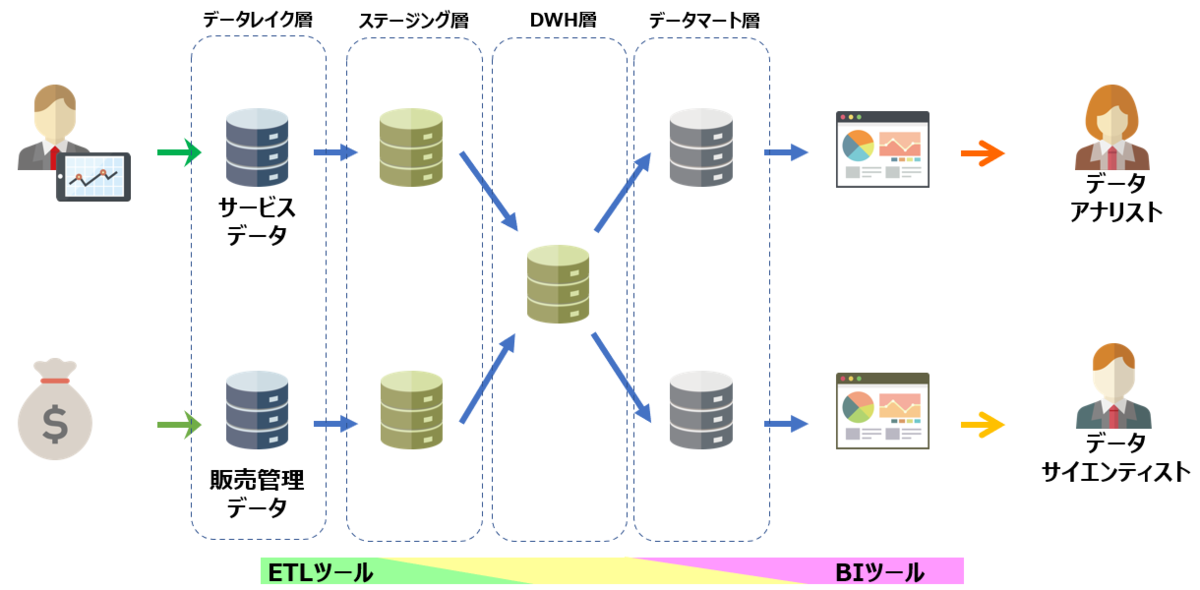
ETL、DWH、BIはそれぞれ様々な製品が存在するとともに、それぞれのツールの機能範囲が重複しているため、境界をどこに設定するかはデータ活用基盤を作成するユーザー次第
- ステージング層
- データレイクに負荷をかけないために、データレイクのレプリカを用意したうえで、レプリカに対してフォーマット変換やデータクレンジングを行う。
- ストレージの低コスト化により、
Extract(抽出)、Load(書き出し)、Transform(変換)の順番で処理されることも増えてきた。
- データマート層
- BIツールがデータ処理を行いやすいように、DWHに格納されているデータのサマリーをあらかじめ作成、管理しておく。
具体的なサービス
AWSを利用する場合
ETLツール(DataGlue)
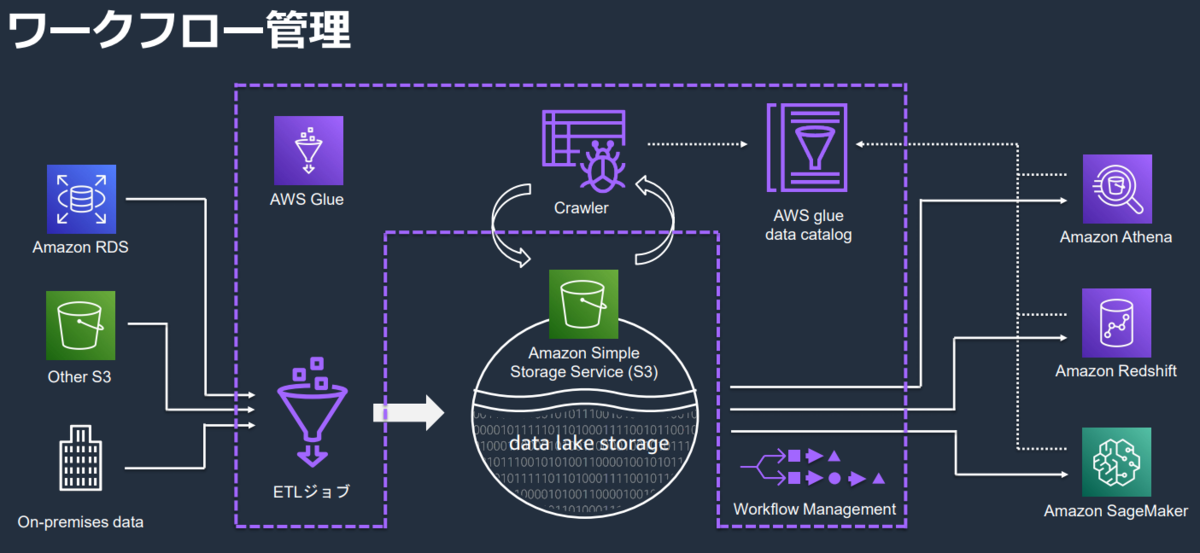
BIツール(QuickSight)
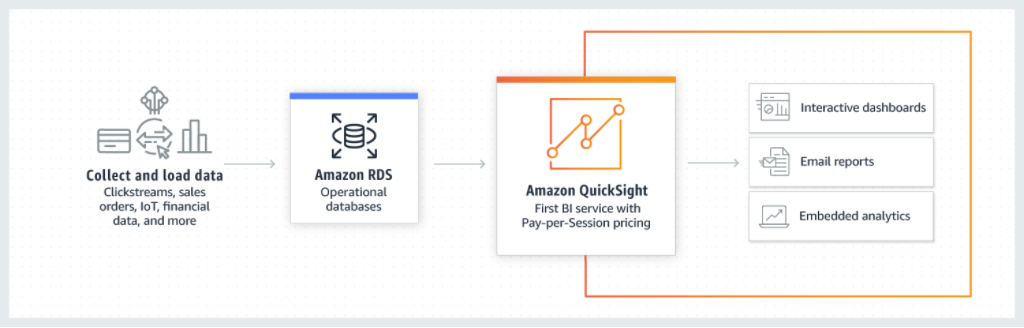
方法1:QuickSight をオペレーショナルデータベース (Amazon RDS など) のデータに接続する
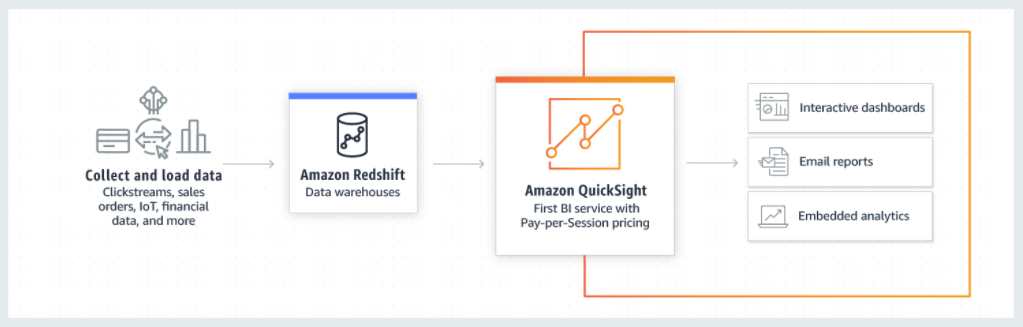
方法2:QuickSight をデータウェアハウス (Amazon RedShift など) に接続する
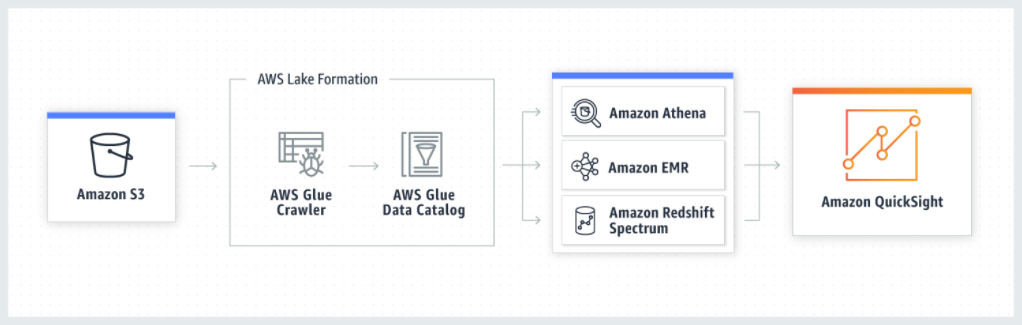
方法3:QuickSight をデータレイク (Amazon S3 など) に接続する
GCPを利用する場合
| ETLツール | DWH | BIツール |
|---|---|---|
| Dataflow | BigQuery | Looker |
その他のサービスを利用する場合
複数のIaaSを想定した場合、データ活用の基盤を一つのIaaSに限定することは得策ではない。そのような場合に備えてIaaSに依存しないツールを選択することも考えられる。
| ETLツール | DWH | BIツール |
|---|---|---|
| Fivetran | Snowflake | Tableau |