Programming Self-Study Notebook:目次
目次
言語系
ミドルウェア系
開発支援ツール
- 「Docker関連のノート」のまとめ
- 「JMeter関連のノート」のまとめ
- 「Jenkins関連のノート」のまとめ
- 「git関連のノート」のまとめ
- 「swagger関連のノート」のまとめ
- 「ESLint関連のノート」のまとめ
- 「Jest関連のノート」のまとめ
- 「bash関連のノート」のまとめ
- 「セキュリティ関連のノート」のまとめ
OS系
- 「Linux関連のノート」のまとめ
- 何をやるにもお世話になる技術です
クラウドインフラ系
開発手法について
その他
「pub add ***」の末尾に赤い文字が表示されたけど、、、

flutterで作成中のアプリにshared_preferencesをaddした際に赤い文字が表示されたので、調べてみました。
エラーの内容
私の環境で表示された文字はいかになります。
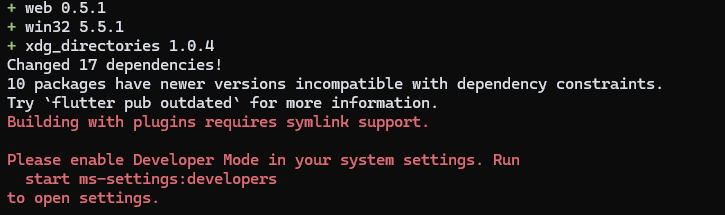
Building with plugins requires symlink support. Please enable Developer Mode in your system settings. Run start ms-settings:developers to open settings.
Google翻訳で訳したところ、以下になりました。
プラグインを使用してビルドするには、シンボリックリンクのサポートが必要です。 システム設定で開発者モードを有効にしてください。 start ms-settings:developers を実行して設定を開きます。
Windows10の設定変更
設定変更が必要そうなので指示に従って対応します。
指示に従って以下のコマンドを入力すると、OSの設定画面が開きました。
start ms-settings:developers
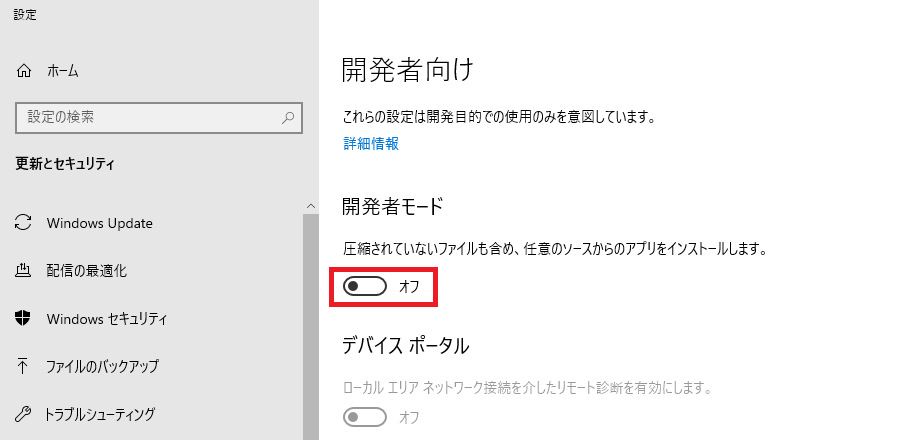
開発者モードがオフになっているのでオンにします。

きっかけのpub add ***を再度実施してみましたが、赤文字は消えていました。
flutterアプリのフォントを変更してみた
flutterのデフォルトフォントはなんとなく好きではないので、自分好みのフォントに変更してみました。
手順1:好みのフォントを入手する
様々なサイトで無料フォントが公開されております。
権利さえあれば何を使用しても構いません。
私は GoogleFont から探すことにしました。

最初に表示された日本語対応フォントのNoto Sans Japaneseを使用することにします。
Noto Sans Japaneseをクリックし、遷移先ページの右上の「Get font」→「Download all」とクリックします。

これにより、Noto_Sans_JP.zipと言う圧縮ファイルがダウンロードされました。
手順2:フォントをプロジェクト内に配置する
次はダウンロードした圧縮ファイルを解凍し、プロジェクト内に配置します。
プロジェクトルートにassets/fontフォルダを作成し、解凍したフォルダをそのままコピーします。
assets/
└── fonts/
└── Noto_Sans_JP/
├── NotoSansJP-VariableFont_wght.ttf
├── OFL.txt
├── README.txt
└── static/
├── NotoSansJP-Black.ttf
├── NotoSansJP-Bold.ttf
├── NotoSansJP-ExtraBold.ttf
├── NotoSansJP-ExtraLight.ttf
├── NotoSansJP-Light.ttf
├── NotoSansJP-Medium.ttf
├── NotoSansJP-Regular.ttf
├── NotoSansJP-SemiBold.ttf
└── NotoSansJP-Thin.ttf
手順3:pubspec.yamlを編集する
pubspec.yaml内のflutterブロックにfontを追加します。
ファイル内をfontで検索すると記述例部分がヒットするので、該当箇所が見つかったら、インデントに気を付けて以下の記述を貼り付けます。
flutter:
fonts:
- family: Noto_Sans_JP
fonts:
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-Thin.ttf
weight: 100
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-ExtraLight.ttf
weight: 200
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-Light.ttf
weight: 300
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-Regular.ttf
weight: 400
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-Medium.ttf
weight: 500
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-SemiBold.ttf
weight: 600
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-Bold.ttf
weight: 700
- asset: assets/fonts/Noto_Sans_JP/static/NotoSansJP-ExtraBold.ttf
weight: 800
- asset: assets/fonts/Noto_Sans_JP/static/Noto_Sans_JP-Black.ttf
weight: 900
uses-material-design: true
編集後に以下のコマンドを実行してください。
- flutter pub get
手順4:フォントを適用する
pubspec.yamlに記述したフォントファミリー名を、MaterialAppのThemeDataのfontFamilyプロパティにセットすることでアプリ全体にフォントを適用することができます。
const MyApp({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
return MaterialApp.router(
routerDelegate: ref.watch(routerProvider).routerDelegate,
routeInformationParser: ref.watch(routerProvider).routeInformationParser,
routeInformationProvider:
ref.watch(routerProvider).routeInformationProvider,
theme: ThemeData(
useMaterial3: true,
fontFamily: 'Noto_Sans_JP',
),
);
}
}
カスタムフォントを適用することができました。
git-secretsで機密情報の混入を防いでみる

git-secretsとはgitへのセキュリティ情報の混入を自動で検出し、セキュリティ情報混入を自動で拒否するためのツールです。
個人PC上でgit-secretsの有効化を行った際の流れや、git-secretsに対して調べた内容をまとめます。
参考文献
git-secretsとは
「非公開のGitリポジトリが攻撃され、コミット履歴上に存在するセキュリティ情報が漏洩し、企業が損害を被る」という事件がたびたび報道されます。 このような事態を回避するために、公開/非公開を問わずGitリポジトリに対しセキュリティレベルに係わる情報や個人情報をプッシュするのは避けるべきです。
git-secretsを利用することで、機密情報がリモートリポジトリにプッシュされる前に、機密情報が混入していることを検知し対象のGitコマンドを拒否することができます。
git-secretsとは、AWSラボが作成したオープンソースです。git-secretsを使用するとGit ソースリポジトリをスキャンし、ユーザーパスワードや AWS アクセスキーなどの機密情報を含む可能性のあるコードや、その他のセキュリティ上の問題があるコードを見つけることができます。
git-secretsは、コミット、コミットメッセージ、マージをスキャンして、シークレットなどの機密情報が Git リポジトリに追加されないようにします。
例えば、コミット、コミットメッセージ、またはマージ履歴のコミットが、設定済みで禁止されている正規表現パターンのいずれかに一致した場合、そのコミットは拒否されます。
前提条件
git-secretsの機能を利用するには以下の条件を満たす必要があります。
- アクティブな AWS アカウント
- Gitクライアント(バージョン 2.37.1以降)がインストールされている
git-secretsのインストールと初期設定
- ローカルマシンでリポジトリをスキャンする場合

手順概要
以下の手順で環境構築を実施します。
- 基本設定
- 追加設定(自動実行の有効化)
- 手順5:git hookを設定する
手順詳細
手順1:Git をインストールする
gitをまだインストールしていない人は、Gitクライアントのインストールを最初に実施する必要があります。Gitクライアントはバージョン 2.37.1以降をインストールする必要があります。
- Gitのインストール手順
手順2:ソースリポジトリをクローンする
スキャン対象のリプジトリがローカル環境に存在している必要があるのでクローンしておきます。すでにクローンされているリポジトリにgit-secretsを追加する場合はスキップ出来ます。
手順3:git-secrets をインストールする(Windowsの場合)
OSによって推奨されるインストール方法が異なります。詳細はgit-secrets内のreadme内に記載されています。
Windowsの場合
3-1:
git-secretsのgitリポジトリをクローンクローンデータを格納するフォルダ(任意)で以下のコマンドを実行します。
git clone https://github.com/awslabs/git-secrets.git3-2:インストールコマンドの実行
クローンしたフォルダの内部に
install.ps1が存在します。PowerShell(管理者)と言うコンソールツール上でgit-secretsに移動し以下のコマンドを実行します。// git-secrets にカレントディレクトリを移動する cd git-secrets // インストールコマンドを実行する ./install.ps1補足(上記コマンド内で実施しているコト)
- 1.
%USERPROFILE%/.git-secretsにgit-secretsとgit-secrets.1をコピー - 2.環境変数PATHに
%USERPROFILE%/.git-secretsを追加
- 1.
補足(コマンド実行時のエラー)
- PowerShellを管理者として実行していてもエラーが出ることがあります。
権限設定が不十分な可能性がありますので確認をお願いします。
Set-ExecutionPolicy RemoteSigned
インストール結果のに対する処理
PS D:\(省略)\git-secrets> ./install.ps1 Checking to see if installation directory already exists... Creating installation directory. Copying files. Checking if directory already exists in Path... Adding to path. Adding to user session. Done.
3-3:Path登録
git-secretsの実行時にGitがそれを取得できるように、PATHのどこかにgit-secretsを配置します。上記コマンドで%USERPROFILE%/.git-secretsを環境変数PATHに追加されているはずですが、追加されていないようであれば追加を実施してください。%USERPROFILE%/.git-secrets
macOSの場合
Homebrewを利用してインストールすることができます。
brew install git-secrets
手順4:コードをスキャンする
スキャンする Git リポジトリのディレクトリに切り替えます。
cd my-git-repository次のコマンドを実行して、リポジトリのスキャンを開始します。
git secrets --scan脆弱性が見つかると出力ファイルを生成します。
以下に出力ファイルの例を示します。
example.sh:4:AWS_SECRET_ACCESS_KEY = ********* [ERROR] Matched one or more prohibited patterns Possible mitigations: - Mark false positives as allowed using: git config --add secrets.allowed ... - Mark false positives as allowed by adding regular expressions to .gitallowed at repository's root directory - List your configured patterns: git config --get-all secrets.patterns - List your configured allowed patterns: git config --get-all secrets.allowed - List your configured allowed patterns in .gitallowed at repository's root directory - Use --no-verify if this is a one-time false positive
手順5:git hookを設定する
プロジェクトのルートディレクトリで以下のコマンドを実施します。
# git hookのインストール git secrets --install # aws認証情報用のパターンをgitconfig(ローカル)に書き込む git secrets --register-aws # リポジトリに設定されているsecretsのconfigを表示 git secrets --list
git-secretsでよく使うコマンド
コマンドの基本形
// git secrets (操作モード) git secrets -–scan
操作モード
| 操作モード | 処理内容 |
|---|---|
| --install | リポジトリのGitフックをインストールします| |
| --scan | 1 つ以上のファイルをスキャンしてシークレットを探します |
| --scan-history | すべてのリビジョンを含むリポジトリをスキャンします |
| --list | git-secrets現在のリポジトリまたはグローバル Git 構成の構成を一覧表示します |
| --add | 禁止または許可されるパターンを追加します |
| --add-provider | シークレット プロバイダーを登録します |
| --register-aws | 一般的な AWS パターンを git 構成に追加し、存在するキーが~/.aws/credentialsどのコミットにも見つからないようにします |
| --aws-provider | INIファイルで見つかった資格情報を出力するシークレットプロバイダー。 |
- オプションの詳細は以下のサイトで確認することができます。
VSCodeのmarkdownプレビューを自分好みにカスタマイズ!

VSCodeのMarkdownファイルのプレビューって見づらくないですか!?
Markdownは手軽に様々な表現ができるので好きなのですが、使用するツールによって行間が広すぎるとか箇条書き開始位置が右過ぎて深くなると行数が増えるとか、、、。利用するツールによって見え方が違うので、見栄えが好みに合わないとせっかくの手軽さが半減してしまう気がします。
VSCodeも例外ではありません。よく使うツールなのですがMarkdownのプレビューはいまいちだな~~と感じていました。
なので、
思い切って見栄えを調整してみることにしました。
概要
流れはものすごく簡単です。
- 環境構築
- 実装(カスタマイズ)
- 手順2:cssの設定を自分好みにカスタマイズする
- 私の設定値で良ければコピペできるように掲載しています。
- ご自由にご利用ください。
- 手順2:cssの設定を自分好みにカスタマイズする
手順1は多くの人が実施済みだと思いますので、実質的にな作業は手順2のみです。
手順2は、どの程度こだわるかにより工数は変わります。
環境構築
手順1:VSCodeにプラグインを追加する
VS Codeの拡張機能で以下のプラグインをインストールします。
手順1:Markdown Preview Enhancedを追加する
- 1-1:VSCodeを起動する
- 1-2:
Extensions(拡張機能)を選択する - 1-3:検索窓に
Markdown Preview Enhancedと入力する - 1-4:
Installをクリックする
※ ↑ 私の場合はインストール済みなので「Installボタン」ではなく「設定ボタン」が表示
Markdown Preview Enhanced内のテーマ
インストールが完了すると、VSCodeの設定画面からMarkdown Preview Enhancedの設定を編集できるようになります。
File->Preferences->Settingsと進みSettings画面を開きます。Settingsの検索窓にMarkdown-preview-enhanced: Preview Themeと入力します。
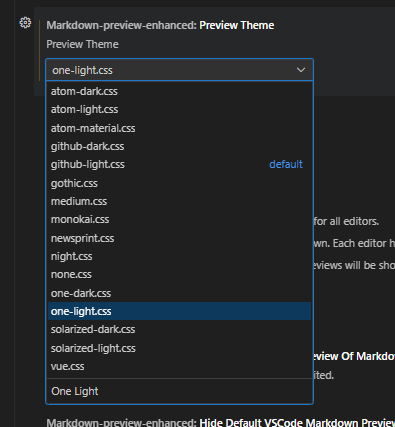
既存のもので良い場合は、以降の作業は不要になります。
手順2:自分好みにカスタマイズする
この後は
style.lessと言うファイルに自分好みの設定を追記していく作業になります- 手順2-1:
Ctrl + Shift + Pで検索窓を表示 - 手順2-1:検索窓に
Markdown Preview Enhanced: Customize CSSを入力- 私は
Globalを編集しました。
- 私は
- 手順2-1:
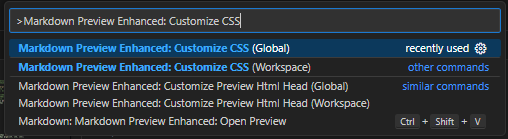
作成結果

設定値
- 以下が私の設定値です
.markdown-preview.markdown-preview { // modify your style here // eg: background-color: blue; h1 { padding: 0.4em 0.5em;/*文字の上下 左右の余白*/ color: #494949;/*文字色*/ background: #eaf4fc;/*背景色*/ border-left: solid 10px #7db4e6;/*左線*/ border-bottom: solid 3px #d7d7d7;/*下線*/ } h2 { position: relative; padding: 0.5em; background: #7db4e6; color: white; } h3 { border-bottom: solid 3px #7db4e6; position: relative; } h4 { border-bottom: solid 3px #cce4ff; position: relative; } }
「弁護士特約」をちょっとだけ使ってみた!

皆さんは交通事故の当事者になってことはありますか?私は先日、自動車事故(もらい事故)の当事者になってしまいました(涙)。
もらい事故なので過失割合0%を主張したのですが、その時に「あらかじめ知っておきたかった」と思うことがたくさんあったので経験談を記載させていただきます。
なかなか事故の当事者になることは無いと思うので、興味がある方の参考になればうれしいです。
事故の状況
簡単にではありますが事故の状況を説明します。
- 事故について
- 朝の通勤時間帯(8時頃)
- 片側2車線(制限速度50km/h)の道路
- 交通量(車両数)が多めの時間帯だったが、渋滞しているわけではないので50km/hで走行可能な状態
- 私の車両も相手の車両も同じ方向に向かいに走行中
- 私の車両は左車線を時速50km程度で直進
- 相手の車両は右側車線を走行(私の車両から見て右側後方を走行していたはず、、、)
- 相手の車両が、方向指示器を点灯せずに左車線に進路変更を行った。(相手が、ウィンカーを点滅させなかったことを認めています。)
- 相手の車両が進路変更の時に斜線境界線を越え左側車線に進入し、左側車線を走行中の私の車両と接触した
- 接触部分は「私の車の
右側面後方(右後ろタイヤ部分)」と「相手の車両の前バンパーの左角」が接触した - サイドミラーはお互いに損傷なし
※ もらい事故と言ってよい状況だと思っています、、、
事故対応について
- すぐに私が警察に通報
- 加入する任意保険の保険会社にも連絡
- 警察官到着後に口頭で状況確認等を実施
最後
- 両者、両車両とも自走可能な状態だったので、警察官の状況確認終了と同時に解散(解散っていうのかな~?)
保険会社とのやり取り
私の保険会社とのやり取り
事故現場で最初の連絡をしていましたが、「レッカー等が無いのであれば、警察対応が終わって少し落ち着てからで大丈夫です」とのことでした。
解散1時間後くらいに連絡を入れ事故登録を行ったところ、担当者が決まったら担当者から連絡をしてもらうことになりました。
そして担当者から連絡があったのが13:00ごろでした。
今回、一連の対応の中で様々な人とやり取りをしましたが、一番良かったのは 「相手の保険会社よりも早く自分の保険会社から電話をもらえたこと、そして的確なアドバイスがもらえたコトです」
以下のアドバイスをもらえました。
過失割合に対する分析
- 状況的に過失割合0%は主張可能です。
- 一般的に車線変更時の接触の過失割合は以下
- 方向指示器をつけていた場合 → 30:70(車線変更した人が70)
- 方向指示器をつけていなかった場合 → 10:90(車線変更した人が90)
- 今回は接触箇所から考えて、後方からの追突に近いので0%の主張も可能。
相手側保険会社の対応の予想
- 「動いている車同士の接触」と言うことで相手側は
10:90を主張する。- 方向指示器を出していなかったと警察官にも証言済み
ドラレコ等の映像がないため、「証拠がない、認識の不一致」を繰り返す。- すぐに「保険会社を教えてほしい」と言ってくるが、いったん伝えない方が良い。
契約保険会社としての対応
- 過失割合0%を主張する場合は、保険会社が手続きを代行できない。
- 過失がある場合の対応が契約の範囲(一般的な話)
- 相手に保険会社を紹介して保険会社間で調整するということは、保険を使うという意思表示になる。
- 保険を使うと
等級や来年以降の保険料に影響してくる。 - 弁護士特約に入っているので、弁護士を紹介可能。
- 弁護士特約があれば、
過失割合0の交渉を弁護士に代行してもらえる。 - 弁護士特約を利用しても保険料や等級に影響しない。
- 弁護士特約があれば、
ポイント 過失割合0を主張する時は、基本的に自分の保険会社が使えない。 だけど弁護士特約をつけていると、弁護士に相談することができる。
相手の保険会社とのやり取り
その日の夕方に以下の会話を行いました。まさに予想通り!
今回の事故は以下の状況
過失割合
10:90が妥当
その他
- 保険会社を教えてほしい(→お断りしました。)
「弁護士特約」の利用
相手側の保険会社と会話していても、「認識の不一致」を繰り返すだけの不誠実な対応が続きそうだったので、弁護士特約を利用することにしました。
「弁護士特約」とは?
自動車保険(任意保険)の弁護士特約をご存じでしょうか?「保険料をできる限り安くしたい!」という理由ですべての特約を外している人も多いのではないかと思いますが、私は万が一の時に気が動転している状態で自分でうまく交渉する自信がないので任意保険に弁護士特約をつけていました。
私が契約している保険会社ではないですが、弁護士特約は一般的なモノなので、参考に記載させていただきます。
- 弁護士費用補償特約 | 強くてやさしいクルマの保険
- 相手方との交渉に弁護士を利用する際の弁護士費用をお支払いする特約です。
- 「もらい事故」など、お客さまに責任のない被害事故のケースでもご利用可能です。
- 弁護士費用補償特約のみのご利用は「ノーカウント事故」扱いです。ノンフリート等級への影響がないため、安心してご利用いただけます。
- 弁護士の紹介も実施してくれる。
「弁護士特約」の利用申告
事故で気持ちが落ち込んでいたのと、相手側の保険会社と平日の昼間にやり取りするのが嫌だったので弁護士特約を利用することにしました。まず契約保険会社に利用したい旨を電話連絡しました。そこで聞いたその後の流れは以下になります。
- 数日で担当弁護士が決まる。
- 担当弁護士から連絡が入る。
- 弁護士によっては電話ではなく直接会ってからでないと担当しない人もいる。弁護士の指示に従ってほしい。
- 事故のやり取りをする前に委任状の作成が必要。委任状なしに開始することはない。
- 委任状のひな型が送られるので、委任状へのサイン、捺印等をする必要がある。
弁護士側の対応ってこんなもの?
この後がひどかった、、、
1週間以上たっても担当弁護士から連絡が無かったので、契約保険会社に状況確認したところ「連絡を受けてから2日後に担当弁護士が決まっている。担当弁護士に状況確認してみる。」とのことでした。
そしてさらに2日後 弁護士から「連絡が遅れてしまい申し訳ない。、、、、」と言葉の後に事故の状況説明を行いました。
一通りの説明をした後に、弁護士から「たかだか一割のために裁判しますか?一割くらい良くないですか?」との衝撃の言葉がありました。
確かにそういう側面もあると思いますが、こちらは自動車保険の弁護士特約の特徴である「もらい事故」など、お客さまに責任のない被害事故のケースでもご利用可能です。と言うことで依頼しています。なのに味方になってくれると思っていた弁護士から相手の主張をそのまま飲むように促されるとは思っていなかったのでショックを受けました。再度、過失割合0になるように交渉したい旨を伝えたその場は終了しました。
その後、いつまでたっても委任状が送られてこないまま時間が経過しました。
私も、ある程度冷静になり、相手側の主張のについて不自然な点等が整理出来てきたので、相手側の保険会社に連絡を入れてみたのですが、
相手側の保険会社は「委任状を送付してもらえることになっているのですでに弁護士と会話をしている。だからおなたとは交渉できないです。」と言うことで会話を遮断されました。
????
「私は委任状を書いていません。そもそもひな型が届いていないので、委任内容の文面も確認できていません。」にも関わらず、 委任状を取り交わしていないのに、委任状を根拠に相手側と交渉を開始している。そのせいで相手側の保険会社と会話できなくなっている?
保険会社・弁護士に確認をしたところ、「送り忘れていました」とのことでした。
さらに1週間後に送られてきたのが、件名等の依頼項目が空の委任状が送られてきて、とりあえず書類に署名・捺印を押すように促されました。
この時点で、弁護士特約の利用を中止いたしました。
その後の交渉と結果
個人での交渉の再開
私の保険会社と相手の保険会社の両方に弁護士特約の利用の中止を伝えたうえで、相手の保険会社と交渉を再開しました。その際に相手の保険会社に伝えたの以下の点になります。
- 引き続き過失割合0を主張する
相手及び相手の保険会社の主張の不自然な点の指摘相手の保険会社に対し相手に対する追加の状況確認の実施の要求- 私の過失割合が
0にならない場合は、再度弁護士特約を利用して裁判まで実施する予定
結果
相手の保険会社が、100%保険適用を認めました。
ただし、100%保険適用を認めたといっても、「認識の不一致はありますが、今回は全て100%負担します」と言うことを言われました。 つまり、「保険会社に対し、裁判費用をかけてまで過失割合10%をキープするよりも、裁判をせずに全額保険適用を認めた方が得」と思わせることができました。
まとめ(自動車保険の「弁護士特約」をちょっとだけ使った感想)
個人的な感想を記載します。一般的に弁護士特約がこんなものなのかの判断は出来ません。 担当になった弁護士の当たりはずれが大きいのかもしえませんが、、、
弁護士をあまり当てにしてはいけない
- 当初は味方に弁護士がいれば、何も困らないと思っていましたが、最後まで弁護士と連携するなら、連携に係わる負担がそれなりに大きい
- 弁護士は自動車保険会社からくる弁護士特約案件の対応が面倒な様子
- 出来る事なら対応したくない様子
- 対応したくないので、「連絡をしない」や「書類を送らない」は当たり前
- 弁護士側は早く終わらせるために、相手と会話する前に依頼者側に依頼を取り下げるように交渉してくる
弁護士特約のメリットは、「こちらは大した負担なく裁判できます。」と言う状況で交渉ができること
- そのうえで、「こちらの要求を飲む方が、裁判するより得じゃないですか?」という選択肢を相手側に提示する
- 実際に裁判をすると、相手側の裁判費用は発生済みなので、交渉力が弱まる。
そして一番重要なのは 「たとえ過失割合0でも、事故に遭わない方が良い」です。
皆さんはなるべく交通事故にまきこまれないように、おきをつけください。
プルリク時の3種のマージ方法を調べてみた
プログラムのコード管理をAWSのCodeCommitで実施することが多いのですが、プルリクに対するマージ処理を正しく理解しておこうと思い、以下の3種類のマージ方法について少し調べてみました。
(ついでにプルリクの処理手順もまとめています。)
- 早送りマージ
- スカッシュマージ
- 3方向マージ
参考文献
コンソール上でのプルリク処理の流れ
プルリクの作成
| No | 画面 | 備考 |
|---|---|---|
| AWSコンソール上でCodoCommitを開いている前提です | ||
| 1 | 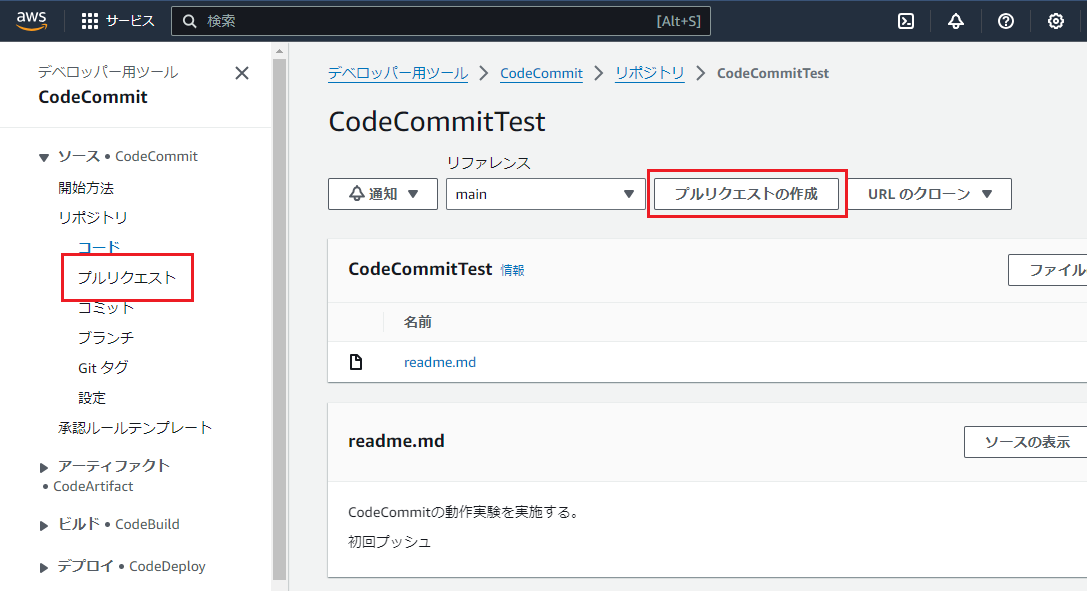 |
プルリクエストの作成を選択 |
| 2 | 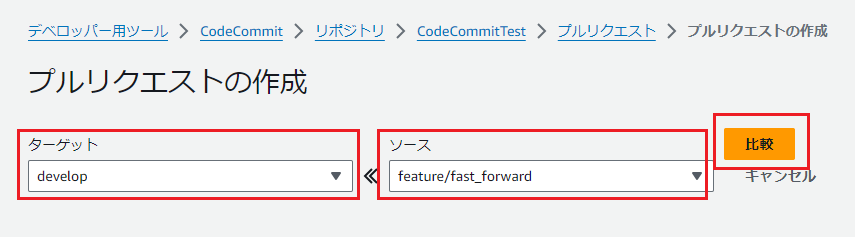 |
ターゲット、ソースを選択してから比較を実施ソース:更新済みのブランチターゲット:更新を取り込みアップデートするブランチ |
| 3 | 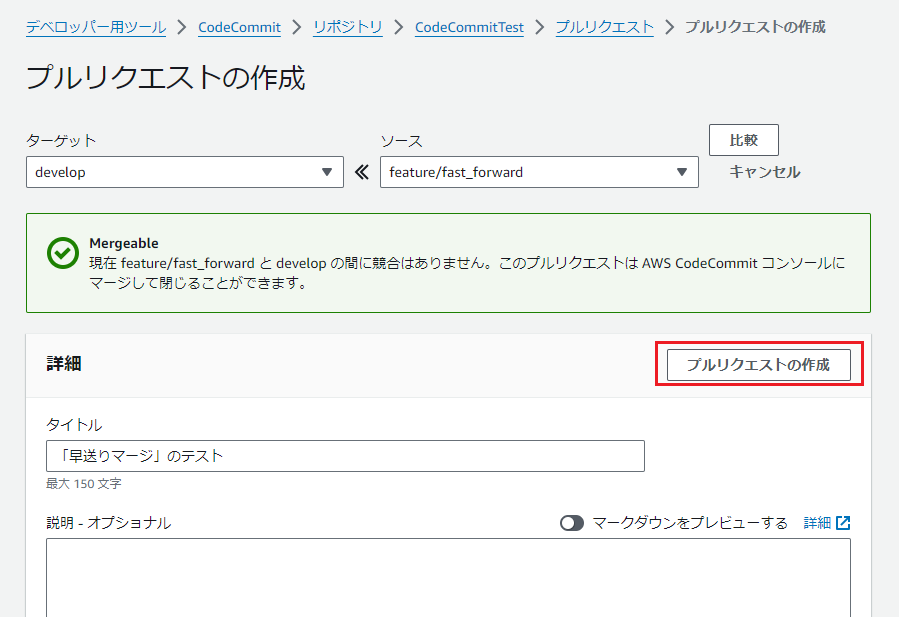 |
説明等を記載してからプルリクの作成を実施 |
| 4 | 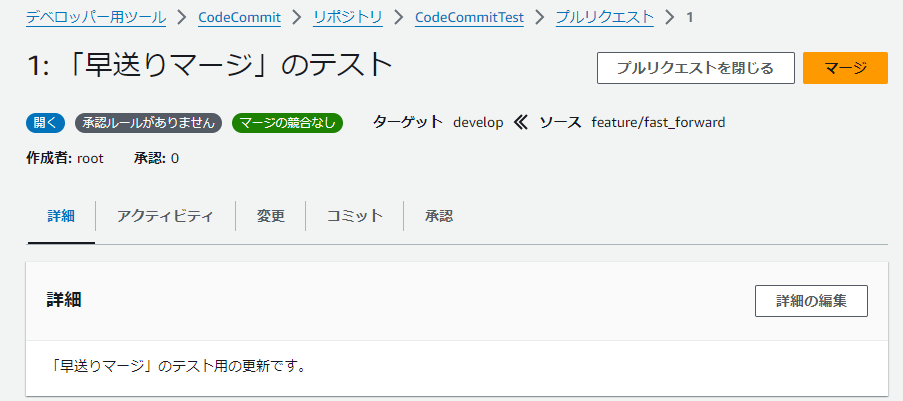 |
プルリクの作成ができました |
ブランチの関係
ソース:更新済みのブランチターゲット:更新を取り込みアップデートするブランチ
プルリクのマージ処理の実施
| No | 画面 | 備考 |
|---|---|---|
| 1 | 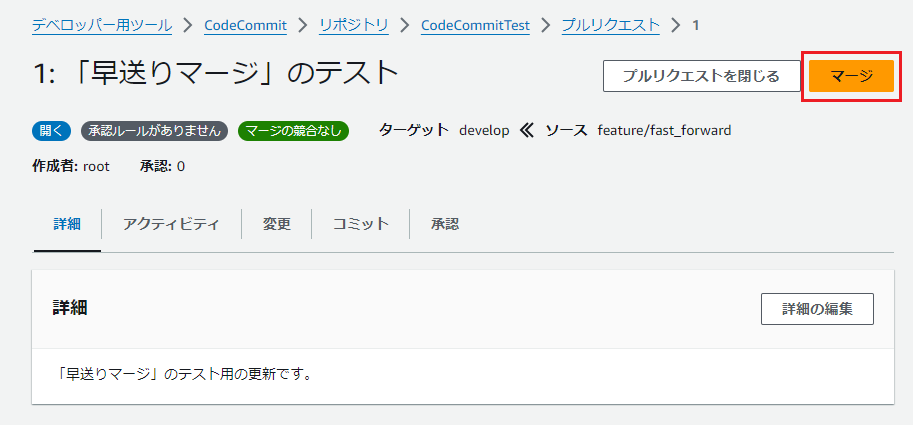 |
|
| 2 |  |
1.マージ戦略を選択します2. ソースブランチの削除の有無を選択します |
ここでは早送りマージを選択 |
||
| 3 | 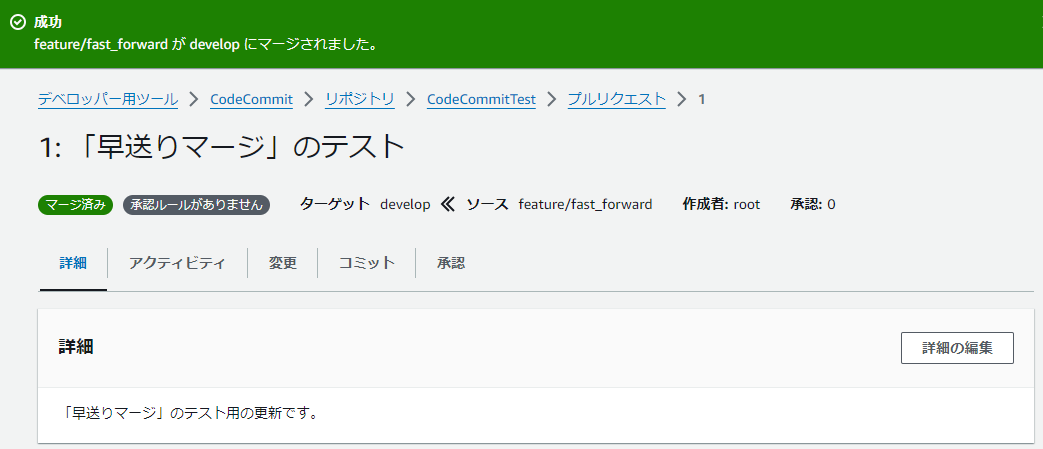 |
成功しました。 |
2.でソースブランチの削除の有無を選択しますが、複数のブランチへマージを実施する想定が無い場合は削除するべきです。
- ブランチが多いと、プルリク作成時にターゲットブランチやソースブランチを探す際に視認性が低下します。
- 別途、手作業でブランチを削除することもできますが、後でブランチ一つづつに対し「削除可能か?」等を判断するのが手間になることが多いです。
マージ戦略の比較
| No | 名称 | コマンド |
|---|---|---|
| 1 | 早送りマージ | merge-branches-by-fast-forward |
| 2 | スカッシュマージ | merge-branches-by-squash |
| 3 | 3方向マージ | merge-branches-by-fast-forward |
AWSのCodeCommitコンソール上では以下のように表示されています。
AWSの CodeCommitコンソール上の表示
実際に3種類のマージを実施した際のブランチツリーがいかになります。
gitのブランチツリーでの見え方 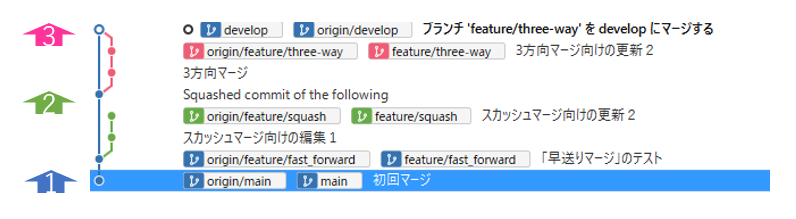
早送りマージ
コマンドフォーマット
aws codecommit merge-branches-by-fast-forward --source-commit-specifier (ソースブランチ名) --destination-commit-specifier (ターゲットブランチ名) --repository-name MyDemoRepo (リポジトリ名)
特徴
オプション設定が少ないことからもわかるように、あまり記録が残らない方法。
イメージ
ソースブランチが通ったルート上を通ってターゲットブランチを進める(ターゲットブランチがソースブランチに追いつく)?
スカッシュマージ
コマンドフォーマット
aws codecommit merge-branches-by-squash --source-commit-specifier (ソースブランチ名) --destination-commit-specifier (ターゲットブランチ名) --author-name "(マージ担当者の名前)" --email "(マージ担当者のメールアドレス)" --commit-message "(マージに関する説明)" --repository-name MyDemoRepo (リポジトリ名)
特徴
- ターゲットブランチ上の複数のコミットをまとめた新しいコミットが作成される
- 作成された新しいコミットが、ターゲットブランチのみにマージされる
- ターゲットブランチとソースブランチは別々のルートを進む(合流することはない)
イメージ
- ソースブランチ上に複数のコミットがあるときに、コミットを1つにまとめたうえでターゲットブランチに渡す
3方向マージ
コマンドフォーマット
aws codecommit merge-branches-by-fast-forward --source-commit-specifier (ソースブランチ名) --destination-commit-specifier (ターゲットブランチ名) --author-name "(マージ担当者の名前)" --email "(マージ担当者のメールアドレス)" --commit-message "(マージに関する説明)" --repository-name MyDemoRepo (リポジトリ名)
特徴
- ターゲットブランチとソースブランチは最後に合流する
イメージ
- ソースブランチ上の更新がターゲットブランチに引き継がれる
まとめ
プルリクの処理手順とマージ戦略による違いを簡単にまとめてみました。- 個人的には「どこからマージされたか?誰がマージしたか?」が一目瞭然な
3方向マージが好きですが、線が複雑になりがちなので好まない人もいると思います。- git上でのプログラムの管理(ブランチ戦略、マージ戦略)はチーム等で様々で良いと思いますが、チーム内では統一されていないと見ずらいですね。
自作アプリを復活させる(その2:開発環境をアップデート!)

はじめに
一度GooglePlayに公開した自作アプリが、知らないうちにリジェクトされ、非公開になっていたので、復活させるためにジタバタしてみることにしました。(以下に前回の内容のリンクを掲載します。)
早速、プログラムを修正するために、VSCodeでプロジェクトのルートを開いたのですが、、、、時間が経ちすぎていてそこからつまずいてしまいました。
最初に結論
- 手順1:古い
AndroidStudioをアンインストールするcache等も削除する必要があるので、他のサイトを参考にしたほうが良いです
- 手順2:最新の
AndroidStudioをインストールする
このあと、私がやった作業手順を記載していますが、ほぼ意味なかったです。
作業環境
私のアップデート前の環境を記述しておきます。
| 項目 | 説明 |
|---|---|
| OS | Windows10 Pro |
| エディタ | AndroidStudio 2020.3.1 |
| Android Gradle プラグインバージョン | 4.2.1 |
| Gradleバージョン | 6.7.1 |
| 開発言語 | Kotlin |
| Gitサービス | AWS CodeCommit |
最近はあらゆるものをVSCodeで開発していたので、最初にVSCodeでプロジェクトを開いてしまいましたが、プロジェクトを開いたときになんとなく馴染まない感じがして、少しの間フリーズしてしまいました。そう、、、この開発で使用していたエディタはAndroidStudioだったのです。(いったいどれ程のことを忘れているのだろう、、、、かなり不安です。)
環境のアップデート
AndroidoStudioを起動したところ懐かしの白キツネ(Arctic Fox)のスプラッシュが表示されるとともに、PCのファンが激しく音を立て始めるのました(何か懐かしい感じがしました)。

そして、以前のアプリ開発時の作業画面がそのまま表示されました。
表示された二つの推奨アップデート
AndroidStudioを起動したところ画面右下に二つのインフォメーションが開きました。
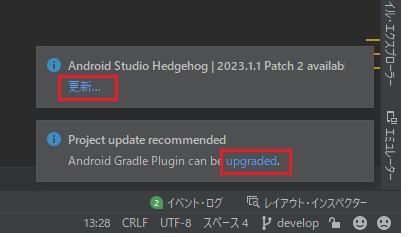
AndroidStudioのアップデート
Android Studio Hedgehog | 2023.1.1 Patch 2 availabGradleのアップデート
Project update recommended Android Gradle Plugin can be upgraded.
と言うことで、まずは上記ツールのアップデートから実施することにします。
AndroidStudioのアップデート
AndroidStudioのバージョン一覧
以下のページでまとめてくれていました。 - Android Studioのバージョン一覧 - 私が利用してるバージョンは当然古いのですが、、、数年でかなり進んでますね、、、、
更新作業
上記インフォメーションの更新ボタンから作業を開始します。(開発中のアプリだと、開発途中での環境変更を躊躇してしまうことがありますが、放置していたアプリなので、迷わずにガンガン進みます。)
| No | 画面 | 備考 |
|---|---|---|
| 1 |  |
赤文字で互換性がなくなる部分があると指摘されました。更新が目的なのでガンガン進みます。 |
| 2 |  |
ブラウザが起動しインストーラーのDL画面へ飛びました。 →DLを開始します。 |
| 3 |  |
規約同意が求められたので、同意して先に進みます。→ android-studio-2023.1.1.28-windows.exeと言うファイルがDLされました。→DLは30秒ほどで完了しました。 |
| (準備) | インストーラーを起動する前に、とりあえずAndroidStudioを閉じます。アンインストールまでは指示されていないので実施しません。 | |
| 5 |  |
|
| 6 |  |
|
| 7 |  |
|
| 8 | 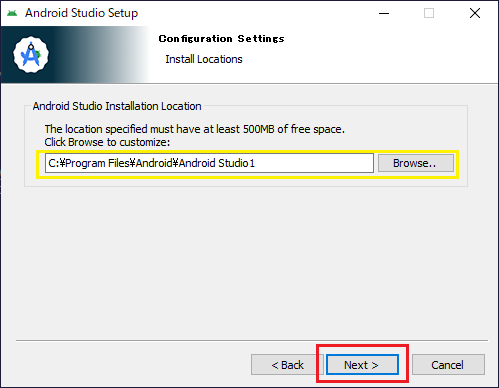 |
LocationがAndroid Studio 1となっていました(同じ階層に前回インストールしたものがAndroid Studioとして格納されていました) |
| 9 |  |
|
 |
(処理中画面) | |
| 10 |  |
30秒程度で終わりました |
| 11 |  |
終了直後に起動確認を行います |
| 12 |  |
起動でエラーが発生してしまいましたが、指示が具体的なので助かります。 |
| 13 | (省略) | まずはcacheの削除を行います。→12の画面を表示したままだと削除できませんでした。→いったんOKで画面を閉じることで、再度が可能になりました。 |
起動オプションで-cleanを指定するためにコマンドプロンプトから起動します。インストール先をメモしておきます。 C:\Program Files\Android\Android Studio1その下に存在する \bin\studio64.exeファイルがアプリの起動ファイルだと予想します。 |
実行コマンド:studio64.exe -clean→失敗(先ほどと同じエラーが出ました。) |
|
| 14 | (PC再起動) | |
| 15 | 実行コマンド:studio64.exe -clean→失敗(先ほどと同じエラーが出ました。) コマンド実行で cacheフォルダが作成されるという無限ループに陥っているようです。↓ AndroidStudioのアンインストールが必要だったみたいですね、、、 |
|
| 15 | AndroidStudioのアンインストールを行います | 以下を見ながらアンインストールを実施しました。 - (参考にしたサイト)https://gihyo.jp/assets/files/book/2021/978-4-297-12138-9/download/AndroidStudio_Delete_20230120.pdf |
| 17 | (PC再起動) | |
| 18 | AndroidStudioのインストーラー起動 | 再度5から11を実施することで、先に進みました。 |
| 19 |  |
|
| 20 |  |
|
| 21 |  |
|
| 22 |  |
|
| 23 |  |
一つづつ選択して同意しました |
 |
(初回起動中) | |
 |
途中で変更の許可が求められます |
|
 |
途中で変更の許可が求められます(2回目) |
|
 |
||
| 24 |  |
とりあえず起動に成功したようです。 既存プロジェクトを開いてみます。 |
| 25 |  |
自分が作成したプロジェクトなので信頼します |
| 26 | 日 |
|
| 27 |  |
便利そうな機能なので入れてみます |
| 28 |  |
右上にバツ印があったので削除しました |
| 29 |  |
Gradleのアップデート
AndroidStudio起動後に次のアラートが表示されていたのでGradleをアップデートすることにします。
メッセージ内容
```
Gradle sync failed in 10 s 433 ms
```
Android Gradle プラグインのアップデート
- 公式ドキュメントを参考にアップデートを行います。
Android Studio をアップデートすると、Android Gradle プラグインを利用可能な最新バージョンに自動的にアップデートするように促すメッセージが表示されることがあります。アップデートに同意するか、プロジェクトのビルド要件に基づいて手動でバージョンを指定するかを選択できます。 プラグインのバージョンは、Android Studio の [File] > [Project Structure] > [Project] メニュー、または最上位の build.gradle.kts ファイルで指定できます。プラグインのバージョンは、その Android Studio プロジェクトでビルドされたすべてのモジュールに適用されます。次の例では、build.gradle.kts ファイルからプラグインをバージョン 8.3.0 に設定しています。
| 変更前 |  |
|---|---|
| 変更後 |  |
※ 公式ドキュメント上ではプラグインのバージョンが8.3.0となっていましたが、AndroidStudioの選択欄では
8.2までしか選択できなかったので8.2.0を選択しました。
- メッセージ的に新しいAndroidStudioでの開発が可能になったようですが、、、またupdateの文字が、、、
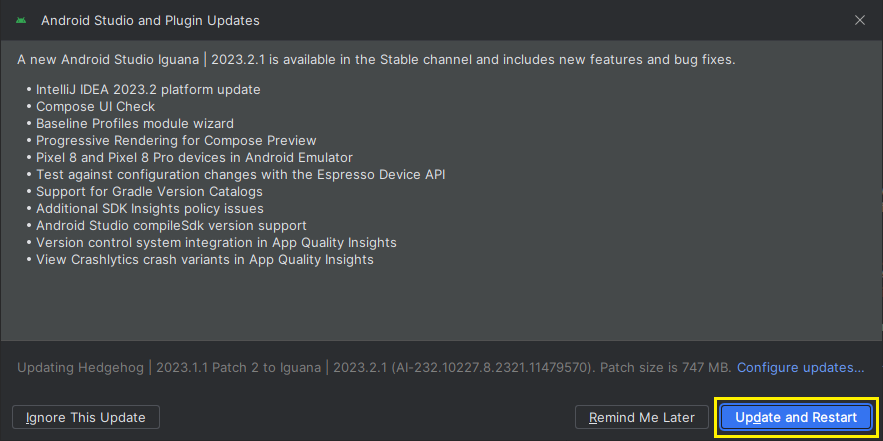
- せっかくなので、さらにアップデートを続けます。
SDKの追加
| No | 画面 | 備考 | |
|---|---|---|---|
| 1 |  |
||
| 2 |  |
||
| 3 |  |
||
 |
|||
| 4 |  |
今回はここまでにします、、、